大模型主流应用RAG
前言
RAG(Retrieval Augmented Generation),检索增强生成(RAG)指的是在使用LLMs回答问题之前,从外部知识库中检索相关信息,本质还是基于提示词工程,根据问题和相关文档进行检索,利用LLM的推理能力和向量数据库的进行语义相识度搜索,将与问题语义相识的文档带入Prompt。
论文:Retrieval-Augmented Generation for Large Language Models: A Survey
基于LangChain+LLM的本地知识库问答:从企业单文档问答到批量文档问答
知识库问答LangChain+LLM的二次开发:商用时的典型问题及其改进方案
Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案
知识库
Embedding Model

分类
基于矩阵分解的方式,代表方式是SVD
基于内容的Embedding:1.静态Embedding(如 word2vec、GloVe 和 FastText), 2.动态Embedding(如 ELMo、GPT 和 BERT)
基于物品序列:item2vec
基于图的Embedding: 分为浅层图模型和深层图模型。浅层图模型有deepwalk、Node2vec、EGES,深层图模型有GCN、GraphSAGE等
1.BAAI/bge-large-zh-v1.5 # HuggingFaceBgeEmbeddings(model=“BAAI/bge-large-zh-v1.5”)
2.GanymedeNil/text2vec-large-chinese/text2vec-base-chinese # 开源版本
3.text-embedding-ada-002 # openai 需要付费
4.models/embedding-001 # google embeddingresult = genai.embed_content( model="models/embedding-001", content="What is the meaning of life?", task_type="retrieval_document", title="Embedding of single string")
嵌入算法:
词嵌入Word Embedding:
句子/文档嵌入 Sentence/Document Embedding:
图嵌入Graph Embedding:
常用嵌入技术:
Word2Vec: Google开发的一种计算词向量的模型,有两种训练架构:CBOW(Continuous Bag of Words)和Skip-gram
Glove:斯坦福大学开发的模型,通过对词与词之间共现概率的矩阵进行分解来学习词向量
FastText(Global Vectors for Word Representation):Facebook开发,和Word2Vec类似,但它在训练过程中考虑了词的内部结构,即子词(subwords)信息
ELMo(Embeddings from Language Models):使用双向LSTM训练得到的深度语言模型来生成词嵌入,能够捕捉词在不同语境中的用法。
BERT(Bidirectional Encoder Representations from Transformers):Google开发,使用了Transformer的Encoder来预训练深度双向表示,可以产生依赖于上下文的词嵌入。
Transformer:不单独是一个嵌入模型,但其编码器和解码器都使用自注意力机制来处理序列信息,并被广泛用于生成上下文敏感的嵌入。
每种嵌入技术都有它的特点和适用场景,选择哪种技术取决于具体的任务需求和资源限制。随着深度学习的发展,越来越多的嵌入模型被提出,并在各种自然语言处理任务中取得了优异的性能向量数据库
推荐使用milvus
collection->segment->entity(搜索中:会搜素Milvus每个segment,并返回合并后的结果)
Sharding-分片:单个 Collection 包含 2 个分片(Shard)
Partition-分区:分区是集合(Collection)的一个分区。Milvus 支持将收集数据划分为物理存储上的多个部分。这个过程称为分区,每个分区可以包含多个段
分区的意义在于通过划定分区减少数据读取,而分片的意义在于多台机器上并行写入操作。
Milvus 允许您将大量向量数据分成少量分区。然后,搜索和其他操作可以限制在一个分区内以提高性能。
Resource Limit Partition 4,096 Shard 64 Field 64 Index 1 Entity unlimited
| 向量数据库 | URL | GitHub Star | Language | Cloud |
|---|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 7.4K | Python | ❌ |
| milvus | https://github.com/milvus-io/milvus | 21.5K | Go/Python/C++ | ✅ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ | ✅ |
| qdrant | https://github.com/qdrant/qdrant | 11.8K | Rust | ✅ |
| typesense | https://github.com/typesense/typesense | 12.9K | C++ | ❌ |
| weaviate | https://github.com/weaviate/weaviate | 6.9K | Go | ✅ |
影响最后实际效果的因素很多
文本分割算法、embedding、向量的存储 搜索 匹配 召回 排序、大模型本身的生成能力
1 如何解决检索出错:embedding算法是关键之一 2 如何解决检索到相关但不根据知识库回答而是根据模型自有的预训练知识回答 3 如何针对结构化文档采取更好的chunk分割:基于规则 4 如何解决非结构化文档分割不够准确的问题:比如最好按照语义切分 5 如何确保召回结果的全面性与准确性:多路召回与最后的去重/精排 6 如何解决基于文档中表格的问答
1.知识库本身语料的格式问题。如果有大量的短文本占据一行或冗余的数据,其表示的意思和信息很有限。因此在做本地知识库的时候,如果前后语句的语义是连贯的但又不在一行,我们需要人工将这些段落做一下整理,将短的文本凑到一行。尽量避免多行的短文本
2.文本分割的效果。很多文本分割的处理方式比较粗暴,就是单纯的按照标点如句号、分号来分割,这其实打断了原本比较连贯的文本,效果不一定好。当然,如果多加上前后几句文本,效果可能会有改善,但是这个度不好控制。比较理想的方式是采用语义分割
1.中文标点符号(正则匹配标点符号) 2.Langchain 的 text_splitter from langchain.text_splitter import CharacterTextSplitter # 按照指定分隔符分割 默认"\n\n"chunk_size=字符长度,chunk_overlap=重复字符(中间重复) from langchain.text_splitter import MarkdownTextSplitter # 沿着Markdown的标题,代码块或水平规则来分割文本 from langchain.text_splitter import PythonCodeTextSplitter # 沿着Python类和方法的定义分割文本 from langchain.text_splitter import RecursiveCharacterTextSplitter # 用于通用文本的分割器。它以一个字符列表为参数,尽可能地把所有的段落(然后是句子,然后是单词)放在一起 from langchain.text_splitter import TokenTextSplitter # 根据openAI的token分割器 from langchain.text_splitter import SpacyTextSplitter # spaCy是一个NLP领域的文本预处理Python库(包括分词,词性标注,依存分析,词性还原,命名实体识别) from langchain.text_splitter import NLTKTextSplitter # 或处理html的分块方式 3.Spacy Text Splitter 阿里达摩院开源的语义分割:nlp_bert_document-segmentation_chinese-base(https://modelscope.cn/models/damo/nlp_bert_document-segmentation_chinese-base/summary) 百度PaddleNLP3.Embedding 模型计算向量以及向量间的相似度,选择不同的模型,这个效果肯定会有差异
MTEB: Massive Text Embedding Benchmark 大规模文本嵌入基准测试
榜单地址:https://huggingface.co/spaces/mteb/leaderboard
**text-embeddings-inference**加速推理
1.BAAI/bge-large-zh-v1.5 # HuggingFaceBgeEmbeddings(model="BAAI/bge-large-zh-v1.5") 2.text2vec-large-chinese /text2vec-base-chinese # 开源版本 3.text-embedding-ada-002 # openai 需要付费 4.models/embedding-001 # google embedding ``` result = genai.embed_content( model="models/embedding-001", content="What is the meaning of life?", task_type="retrieval_document", title="Embedding of single string") ``` 5.GanymedeNil/text2vec-large-chinese4.大模型本身的能力,如现在 chatgpt-4 应该是傲视群雄,大模型基本是分为 chatgpt-4 和其他了。当然,使用 chatgpt 本身有信息安全问题以及费用问题。国内清华开源的 chatGLM-6b 是一个效果和性价比尚可的替代
1.语料处理
LlamaIndex (formerly GPT Index) is a data framework for your LLM applications
2.Text Splitter
3.Embedding选择
4.LLM选择和集成
打造智能客服:LLM和本地 知识库的完美协同原理
召回文档怎么结合LLM
Sutff:将检索retrieval的相应文档给到prompt上下文context中
refine: 不断拿出一个检索的文档给到prompt的上下文,在将这个过程进行迭代
map reduce: 每个文档给到prompt得到答案,将所有答案合并再去推理
map re-rank: 每个文档的回答进行打分,rank后拿到最佳
RAG优化
检索增强生成(RAG)有什么好的优化方案?
基础
文档块切分:设置适当的块间重叠、多粒度文档块切分、基于语义的文档切分、文档块摘要\ 文本嵌入模型:基于新语料微调嵌入模型、动态表征。 提示工程优化:优化模板增加提示词约束、提示词改写。 大模型迭代:基于正反馈微调模型、量化感知训练、提供大context window的推理模型 还可对query召回的文档块集合进行处理,比如:元数据过滤[7]、重排序减少文档块数量[2]RAG架构优化
经典的RAG架构中,context增强只用到了向量数据库。这种方法有一些缺点,比如无法获取长程关联知识[3]、信息密度低(尤其当LLM context window较小时不友好)
那此题是否可解?答案是肯定的。一个比较好的方案是增加一路与向量库平行的KG(知识图谱)上下文增强策略。其技术架构图大致如下
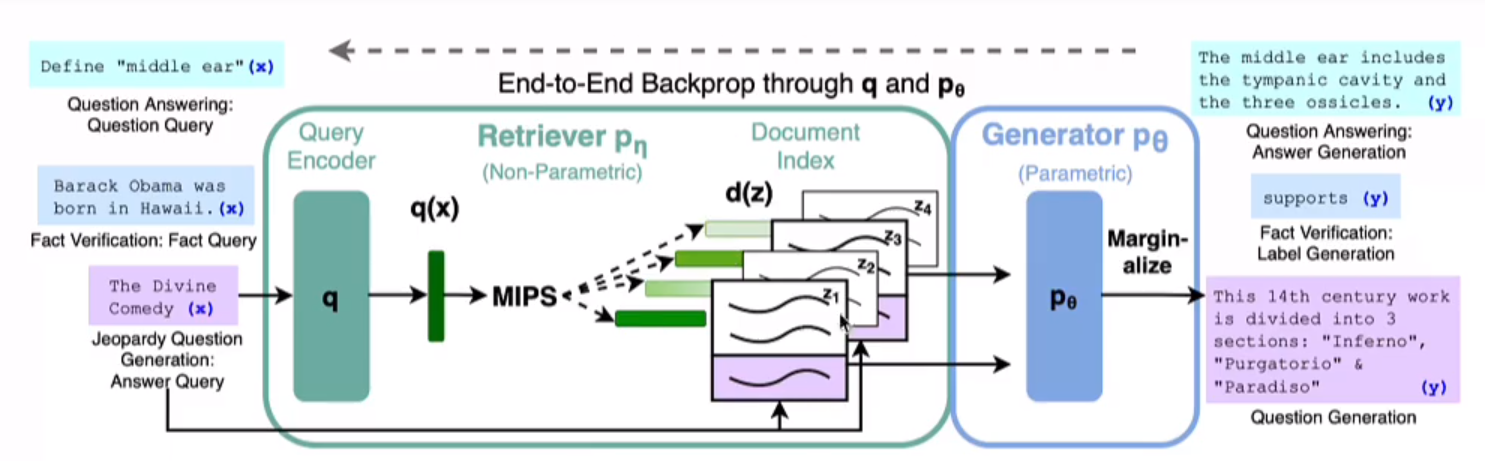
RAG(更适合知识密集性场景)三种类型
Naive RAG
Advanced RAG
Modular RAG
论文地址https://arxiv.org/pdf/2312.10997.pdf
RAG的成功要求:一个成功的RAG系统应该有两个主要功能:检索必须找到与用户查询最相关的文档,生成必须有效地利用这些文档来回答用户查询
Naive RAG索引问题优化: 增强数据粒度,优化索引结构,添加元数据,对齐优化,混合索引
索引问题优化的目标是: 提高文本的标准化(去除不相关的信息和特殊字符)/一致性(消除实体和术语中的歧义和重复或冗余的信息),确保事实的准确性以及上下文的丰富性,以保证RAG系统的性能
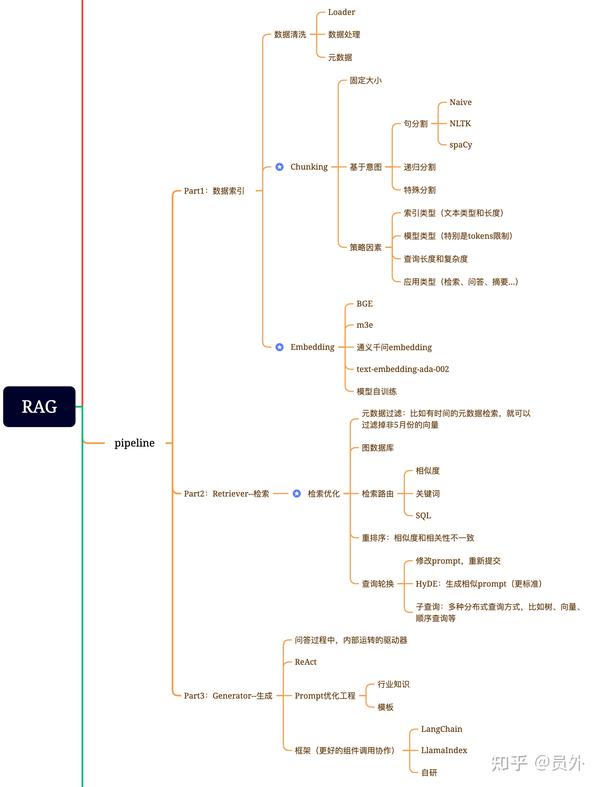
1.数据索引
包括:数据提取和清洗原始数据/分块chunking(LLM有上下文长度限制)/向量化embedding 等方面1.增强数据粒度
采用不同的分块方式 1.基本的字符数分割(chunk_overlap中间重复字符) 2.标点符号(换行符/句号)/文档的固有结构分割(Markdown/html) 3.语义分割(SpacyTextSplitter/NLTKTextSplitter/或阿里达摩院nlp_bert_document-segmentation_chinese-base分割模型)2.优化索引结构
调整块的大小,尽可能收集相关信息并减少上下文噪声3.添加元数据信息
将引用的元数据嵌入到块中,例如用户筛选的日期和目的,通过过滤元数据来提高效率和相关性4.对齐优化
解决对齐问题和之间的差异文件,包括引入假设问题,创建适合每个文档回答的问题2.检索召回retriever(5-10个Topk最优)
检索召回存在的问题:主要是检索质量问题 1.精度低,检索集中并非所有块都与查询相关 2.低召回率,所有相关块没有全部被召回,LLM没有获得足够的上下文1.元数据过滤
过滤掉不相关的文本,以便于减小检索范围提高检索结果的相关性2.混合搜索
利用不同搜索技术的优势,如基于关键字的搜索,语义搜索和矢量搜素来适应不同的查询类型和信息需求,确保对最相关和上下文丰富的信息的一致搜索。混合检索可以作为检索策略的有力补充,增强RAG管道的整体性能3.重排
3.生成generation
1.Prompt压缩
压缩不相关的上下文,突出关键段落,减少整体上下文长度2.指令instruction优化
将问题进行分解(查询转换) 1.查询语句的相关性复制:(通过LLM将查询转换为多个相似但不同的查询) 2.并发的向量搜素:(对所有查询执行并发的向量搜索) 3.智能重新排名:(聚合和细化所有结果使用倒数排序融合RRF) 倒数排序融合(RRF):是一种将具有不同相关性指标的多个结果集组合成单个结构集的方法,组合来自不同查询的排名,非常适合组合来自可能具有不同分数尺度或分布的查询结果 倒数排序融合RRF(https://zhuanlan.zhihu.com/p/664143375)3.嵌入Prompt
1.stuff:所有检索的文档填充到Context中 2.refine: 迭代:每个文档填充到Context 3.map reduce: 合并推理(每个文档填充到Context给LLM得到Answer) 4.map re-rank: 每个文档的回答进行打分,rank后拿到最佳3.专家LLMs选择
参考项目
LangChain-ChagGLM-Webui
https://github.com/X-D-Lab/LangChain-ChatGLM-Webui/tree/master
Langchain-Chatchat
https://github.com/chatchat-space/Langchain-Chatchat?tab=readme-ov-file
LongChainKBQA
https://github.com/wp931120/LongChainKBQA
https://blog.csdn.net/zyqytsoft/article/details/131159174
1.AIGC生成系统 2.GPT和AI agent 3.知识库问答