RabbitMQ Note
什么是MQ
AMQP:即Advanced Message Queuing Protocol,是一个应用层标准高级消息队列协议,提供统一消息服务。是应用层协议的一个开放标准,为面向消息的中间件设计。类似于一种FIFO先入先出队列
为啥要用MQ?
>1.高并发的流量削峰 >2.应用解耦 >3.处理异步任务 >4.消息分发常见MQ:
RabbitMQ
>由erlang语言开发,性能较好,吞吐量到万级,MQ功能比较完备,消息投递和消费可靠,稳定易用支持多种语言Kafka
>大数据的杀手锏,性能卓越,吞吐量高,单机写入 TPS 约在百万条/秒,时效性 ms 级,可用性非常高;其次kafka是分布式的RocketMQ
>RocketMQ 出自阿里巴巴的开源产品,用 Java 语言实现
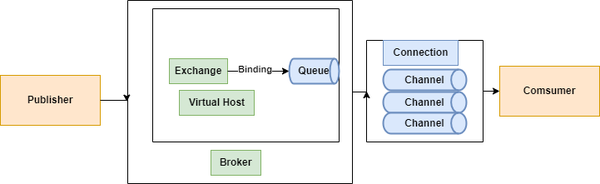
名词解释
Broker: 接收和分发消息的应用,
RabbitMQ Server就是Message BrokerVirtual host: 出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的
namespace概念。当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue等Connection:
publisher/consumer和broker之间的TCP连接Channel: 如果每一次访问
RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也低,Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销Exchange: message到达broker的第一站,根据分发规则,匹配查询表中的
routing key,分发消息到queue中去。常用的类型有:
direct(point-to-point),topic(publish-subscribe) and fanout(multicast)Queue: 消息投递到queue,等待consumer消费
Binding: exchange和queue之间的虚拟连接,binding中可以包含routing key,Binding信息被保存到exchange中的查询表中,用于message的分发依据。
RabbitMQ Exchange分类
常用的有direct,fanout,topic,headers
direct:
1:1,binding key和routing key都是队列的名称fanout:
1:N,不需要处理Route key,把消息路由到与该Exchange绑定Binding的所有Queuetopic:
N:1,多个exchange路由到同一个queue,根据routing key的模糊匹配headers:
不处理routing key,根据发送的消息内容中的headers属性(及参数)与绑定时指定的键值对进行匹配
direct Exchange:
是RabbitMQ Broker的默认Exchange它有一个特别的属性对一些简单的应用来说是非常有用的,在使用这个类型的Exchange时,可以不必指定routing key的名字,在此类型下创建的Queue有一个默认的routing key,这个routing key一般同Queue同名。
RabbitMQ的工作模式:
1.simple模式
一对一,不需要指定exchange,使用默认的 direct exchange
producer -> queue -> consumer
2.worker模式
使用默认的direct exchange,一对多
producer ->queue -> consumer1,consumer2,consumer3有多个消费者,消息被均分给多个消费者处理,两种分发方式:
(1.轮询分发:平均分配,必须采用自动应答autoAck
(2.公平分发:能者多劳(需要修改配置:1.消息确认改为手动ack,2.预处理模式qos参数=1,为每次读取一条消息)>高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize) 保证一条消息只能被一个消费者使用
3.发布订阅模式
使用fanout exchange,publish/subscribe,消息投递到每个绑定的queue中
producer -> fanout exchange-> queue1,queue2,queue3 -> consumer1,consumer2,consumer3
4.routing路由模式
使用direct exchange,发送消息时指定routing key,以此投递消息到指定queue
producer -> direct exchange -> queue1,queue2,queue3 -> consumer1,consumer2,consumer3
5.topic主题模式
使用Topic exchange,发送消息时候指定routing key,根据routing key模式匹配,消息被投递到一个或多个队列中
#:代表0,1,多个 *:至少有一个
6.RPC模式
RabbitMQ 消息确认机制ACK
1.生产者发送消息确认分为:Confirm消息确认(将信道设置成Confirm模式,成功失败都有返回)和Return(投递失败时才有返回)消息机制
2.消费者采用ack模式:自动ACK: 消费者接收到消息后自动发送ACK给RabbitMQ 手动ACK: 手动控制消费者接收到并成功消息后发送ACK给RabbitMQ
持久化
设置了队列和消息持久化后:
当服务重启之后,消息仍然存在只设置队列持久化,不设置消息持久化:
重启之后消息会丢失只设置消息持久化,不设置队列持久化:
在服务重启后,队列会消失,从而依附于队列的消息也会丢失,毫无意义>exchange和queue:通过durable参数设置 >消息:通过properties = pika.BasicProperties(delivery_mode=2)设置
预取值
消息的发送就是异步发送的,所以在channel上肯定不止只有一个消息,消费者的手动确认也是异步的,就存在一个未确认的消息缓冲区,因此希望能限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题
通过使用basic.gos,方法设置“预取计数”值来完成的定义通道上允许的未确认消息的最大数量。一旦数量达到配置的数量,RabbitMQ将停止在通道上传递更多消息
prefetch预取值可以用来限流
死信队列:
死信,就是无法被消费的消息,由于某些原因导致queue中的某些消息无法被消费,则将这些消息投递到
死信队列死信可能的原因
>1.消息TTL过期 >2.队列达到最大长度(队列满了,无法再添加数据到mq中) >3.消息被拒绝
消息丢失?
从三个方面解决:
1.生产者确认机制
>开启生产者确认机制Confirm:只要消息成功发送到交换机之后,RabbitMQ就会发送一个ack给生产者(即使消息没有Queue接收,也会发送ack)。如果消息没有成功发送到交换机,就会发送一条nack消息,提示发送失败 >事务机制:在一条消息发送之后会使发送端阻塞,等待RabbitMQ的回应,之后才能继续发送下一条消息。性能差2.消费者手动确认
3.持久化
延迟队列
存储对应的延迟消息,指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费
消息重复消费怎么处理?
1.生产时消息重复
2.消费时消息重复
由于网络波动,导致消息确认没有收到
解决方法:
>发送消息时让每个消息携带一个全局的唯一ID,在消费消息时先判断消息是否已经被消费过,保证消息消费逻辑的幂等性
Other
>exclusive:指示队列是否是排他性。如果一个队列被声明为排他队列,该队列仅对首次申明它的连接可见,并在连接断开时自动删除。 1. 排他队列是基于连接可见的,同一连接的不同信道Channel是可以同时访问同一连接创建的排他队列; 2.“首次”,如果一个连接已经声明了一个排他队列,其他连接是不允许建立同名的排他队列的,这个与普通队列不同; 3. 即使该队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除的,这种队列适用于一个客户端发送读取消息的应用场景。 >autoDelete:是否自动删除。如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于发布订阅方式创建的临时队列 >mandatory: >当消息无法找到对应的queue时 >mandatory :true 返回消息给生产者 >mandatory: false 直接丢弃rabbitmq内存磁盘监控
>内存使用超过配置的阈值,或磁盘剩余空间低于配置的阈值会警告,rabbitmq连接会被挂起 rabbitmqctl set_vm_memory_high_watermark.relative=0.4-0.6 rabbitmqctl set_vm_memory_high_watermark.absolute=2GB rabbitmqctl set_disk_free_limit 100GB >内存换页,内存使用率达到一定值,将内存中数据转入磁盘中 vm_memory_high_watermark_paging_ratio=0.7
rabbitmq集群搭建
1.停止rabbitmq服务
2.启动第一个节点
sudo RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit-1 rabbit-server start &
3.启动第二个节点
sudo RABBITMQ_NODE_PORT=5673 RABBITMQ_SERVER_START_ARGS=“-rabbitmq_management listener [{port,15673}]” RABBITMQ_NODENAME=rabbit-2 rabbitmq-server start &
4.修改rabbit-1为主节点
sudo rabbitmqctl -n rabbit-1 stop_app # 1.停止应用
sudo rabbitmqctl -n rabbit-1 reset # 2.重置,清除节点上的历史数据(否则无法加入节点)
sudo rabbitmqctl -n rabbit-1 start_app # 3.启动应用
5.修改rabbit-2为从节点
sudo rabbitmqctl -n rabbit-2 stop_app
sudo rabbitmqctl -n rabbit-2 reset
sudo rabbitmqctl -n rabbit-2 join_cluster rabbit-1@主机名
sudo rabbitmqctl -n rabbit-2 start_app
6.验证集群状态
sudo rabbitmqctl cluster_status -n rabbit-1